The Pursuit of (E-book) Page Numbers

I consider myself an e-book aficionado. While there’s nothing that beats sitting down with a real book and a cup of something warm as a way to relax, there’s rarely any time to do so. E-books offer a great way to save space, travel light, and (what’s really exciting) get my hands on books in other languages that I might have no other way of purchasing otherwise.
This semester at MIIS I had the chance to take a class on Desktop Publishing taught by Max Troyer. As someone who is very fond of mixing language, design, and tech, I was very excited to look at the DTP process — which I had already had a modicum of experience with — through the lens of localization. And color me surprised that two whole weeks of this class were devoted to localizing e-books.
When the time to choose our final projects came along, I jumped at the chance to deepen my knowledge of the e‑book creation process. I already had five years of experience with Photoshop and InDesign thanks to my past as an active member of a nationally competitive yearbook staff in middle and high school, so I wanted to take on something I felt less comfortable with, though it would seem to be much simpler at first glance.
I learned that first glances are misleading. I learned that the world of e-books is full of publisher-enabled software gatekeeping. I also learned how to work with e-books, pose questions, try to answer them, and troubleshoot. To be honest, I failed at achieving my most lofty goal, but I succeeded in learning a lot more about working with e-books and the translation than I knew before.
But I’m getting ahead of myself.
Step 1: Defining the Problem
E-books are convenient, yes, but they’re also tough to synchronize in the physical realm. If you’re attending a book club and Barbara is referring to something that happened on page 42 of the physical edition, you might have a hard time finding that page in your e-book. Or you would, back before Kindle introduced a neat little update that would synchronize its digital editions with the page numbers of a physical copy of a book.
I was also familiar with the commendable work of the Russian Virtual Library in providing a free library of high-quality works in Russian that correspond directly to well-edited collected works of classical authors. These files include the real page numbers embedded in the text, so that the text can be cited if necessary.
This led me to wonder how that aspect of a text might be handled in a localization project. I set two goals before myself: (1) to figure out how to make page numbers in a regular (.epub) e-book, and (2) whether I could make page numbers appear in a .mobi file I uploaded to my kindle. So I chose one of my favorite books by Nikolai Gogol, Dead Souls, and set out to mock translate it into an English-language e-book, finding the answers to my questions at the same time.
Step 2: The Translation Process
I took advantage of this project to learn another translation tool. I’ve already had experience with Trados and MemoQ, whereas my experience with Google Translator Toolkit was minimal. Having chosen my toolset, I downloaded my assets from their online home, uploaded them to GTT, and was dismayed to find that I left the program “thinking.”
I refreshed a couple of times, was about to try to take it all to Wordfast, and then looked at the time on my computer and threw my hands up in the air.
The next morning, what would you know? There it was, all bundled up and ready to work.
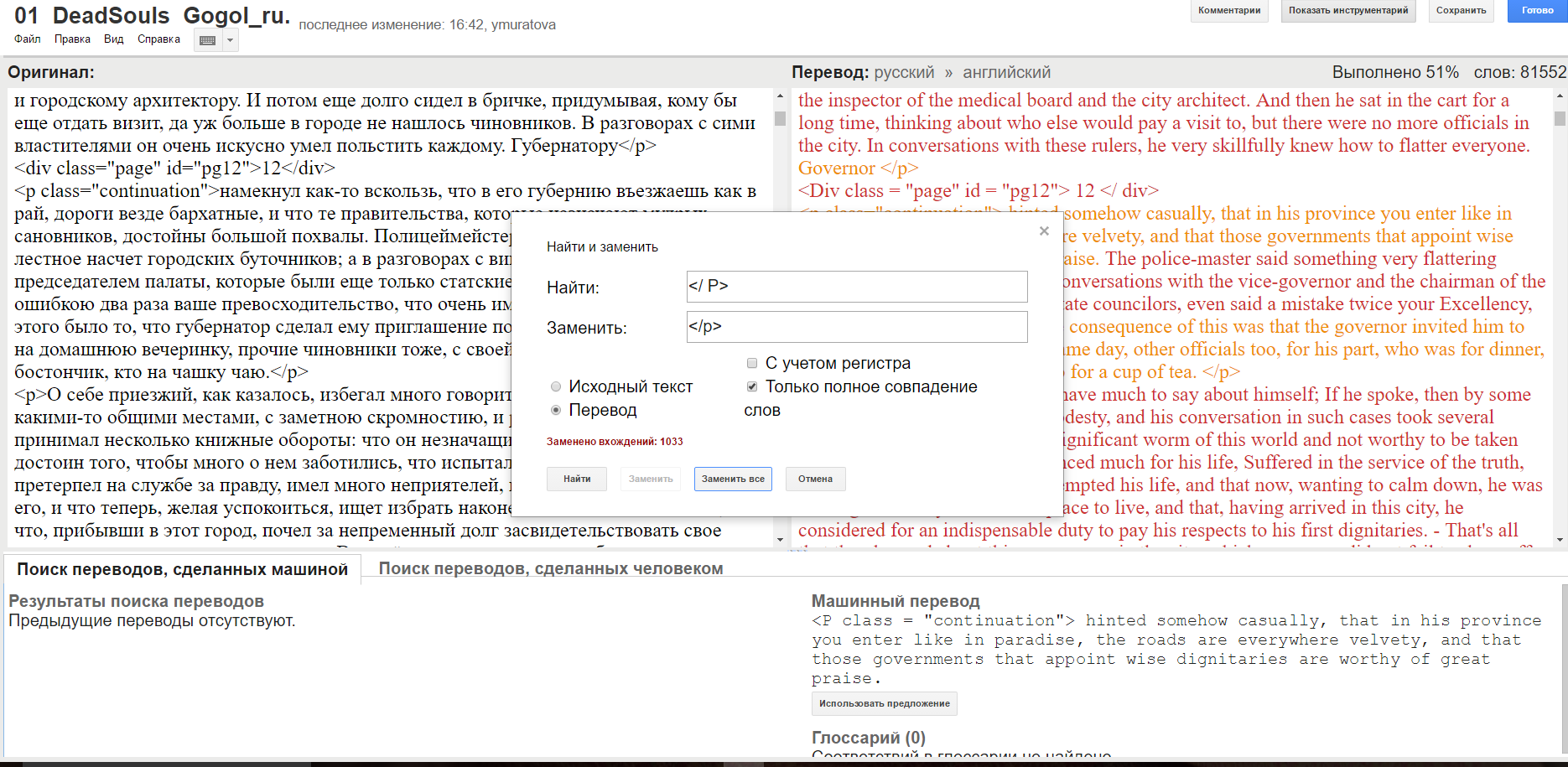
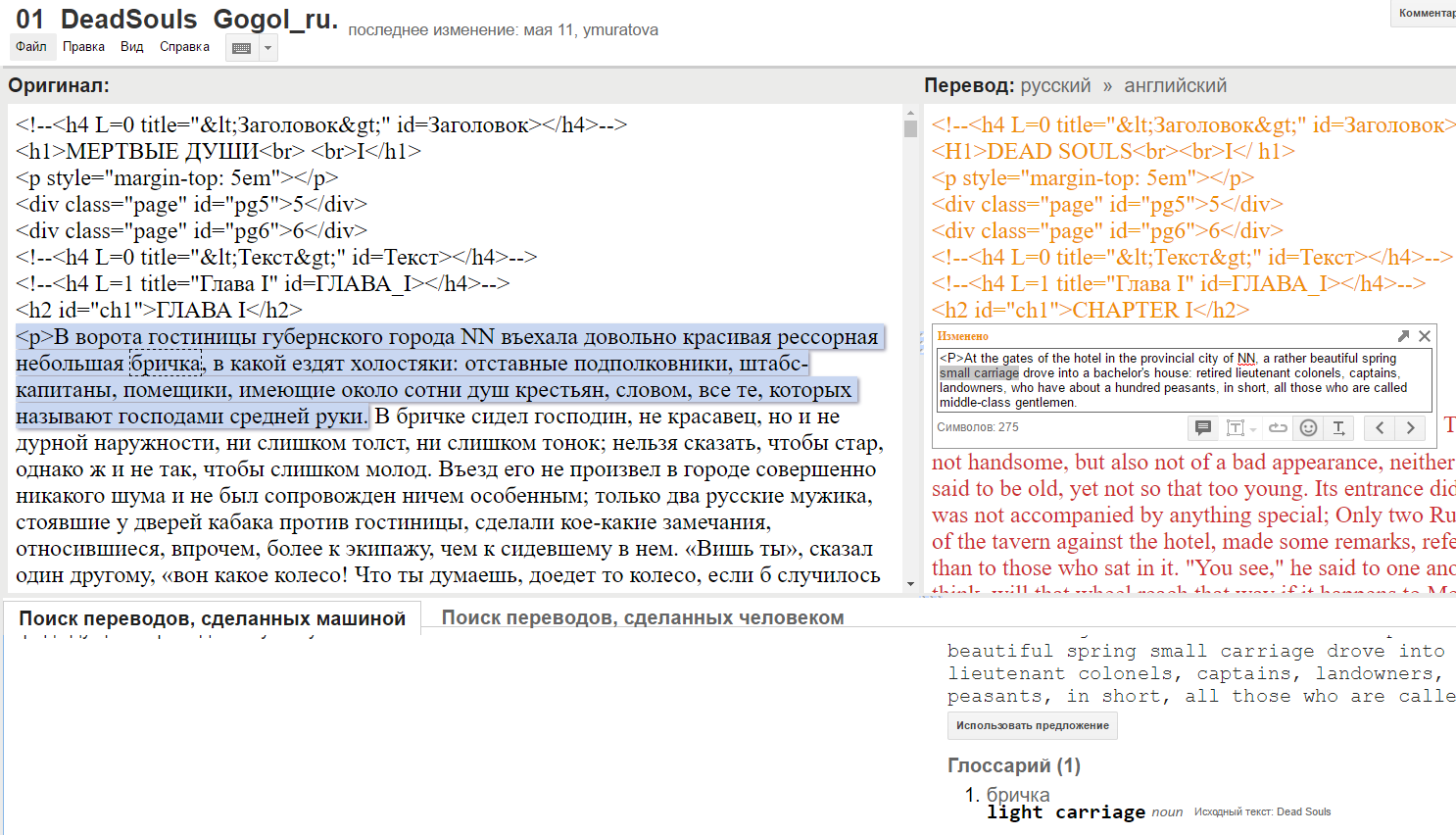
The size made it a bit hefty to work with, there were a suitable number of processing slowdowns in the work, but I managed. An unfortunate reality was the lack of processing for the file’s HTML. In theory, GTT is supposed to automatically insert placeholders everywhere it finds tags. As the image below shows, that didn’t really happen.
In fact, it even tried translating and editing some of it by adding spaces and other extraneous symbols. I’m assuming some of the unusual coding and the file’s size may be to blame. In any case, I managed by making liberal use of GTT’s Find and Replace function.
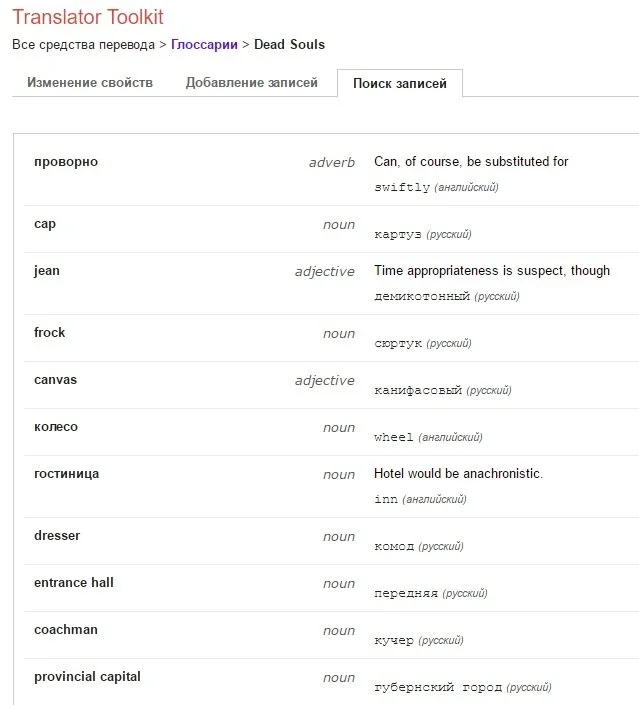
Next, even though the actual translation process was largely relying on non-edited machine translation, I did want to get a handle on using some of GTT’s terminological features. GTT uses its own custom file for glossaries, so I used their guidelines for creating a Glossary in Google Sheets, saved it as a .csv file and uploaded it to GTT. Lo and behold, it worked!
From there, I could browse the glossary at my leisure, or activate it for a certain project. In that case, you can see the glossary entry at the bottom right hand corner of the user interface when a certain sentence containing that word is selected. Buoyed by my success, I finished my patching of the mildly mangled code and exported it to begin my foray into e-book creation.
Part 3: Code Crafting
Next began the process of taking that code and fitting it into a functional ePub document that could display pages. Sigil was my weapon of choice for this. I started with the process we used in class for a basic e-book. I opened a new file, added a cover, metadata, and the like. Then I pasted in the translated file and started to break the file into separate chapters. Having done that, I started dealing with coding in the page numbers.
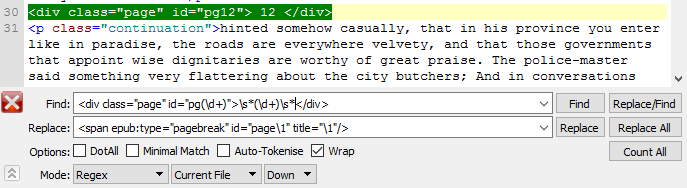
If your source doesn’t have the real page numbers marked, you’ve got to put them in yourself. I was lucky enough that the page numbers were already denoted in the html, and all I had to do was change the tags to fit the e-book standard. Finding out how to do this properly was a hassle. It took a lot of digging through dead-ends and vague explanations in forums, but I finally found a place to start.
The first thing to look is to look at the ePub3 Accessibility Guidelines for how to denote page numbers. At that point, I had to use Sigil’s Find and Replace function with Regular Expressions enabled in order to take the code that was there and replace it with the code that should be there. Prior to this project, I had had minimal experience with regular expressions, so finally getting to roll up my sleeves and figure out how they work was really satisfying.
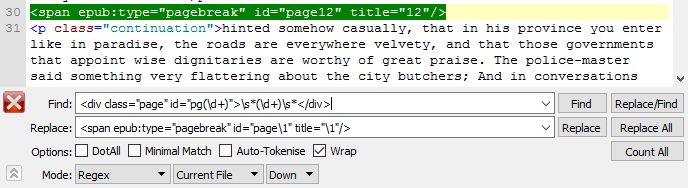
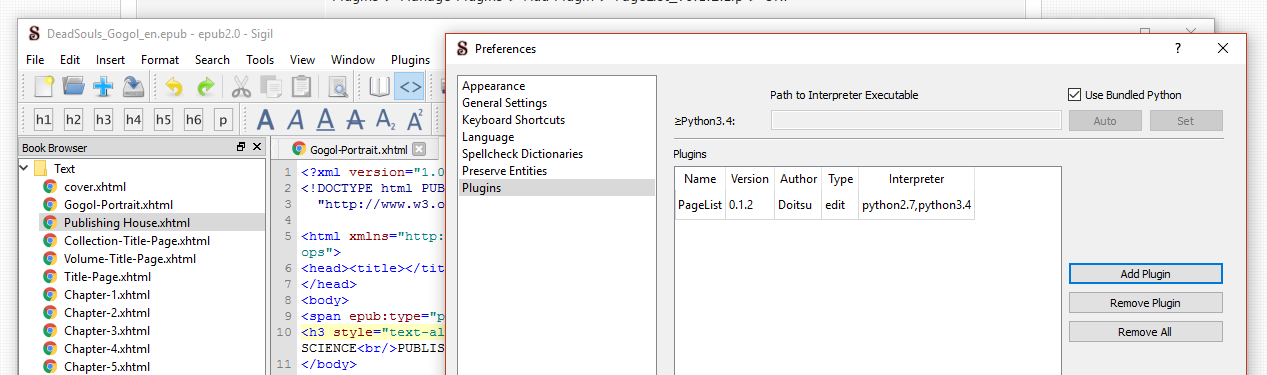
Next came the plugins. In order to see page numbers, you’ll need the file to have a page list and convert it to ePub3. First, I installed Doitsu’s Page List Plugin. There is some prep work that goes into making this plugin work. It’s explained in the linked discussion, but you need to update the tag that denotes what specific version of html that you’re working with. After you do that, ePub check won’t work anymore, so you need to make sure your code is good beforehand. Run that plug-in and check your NCX file to make sure that the page list was added.
Second, I took that file and ran KevinH’s ePub3-itizer Plugin. This gave me an ePub3 that I could open in Adobe’s Digital Editions and see the Page List for. What a sound of joy came out of my mouth when this happened!
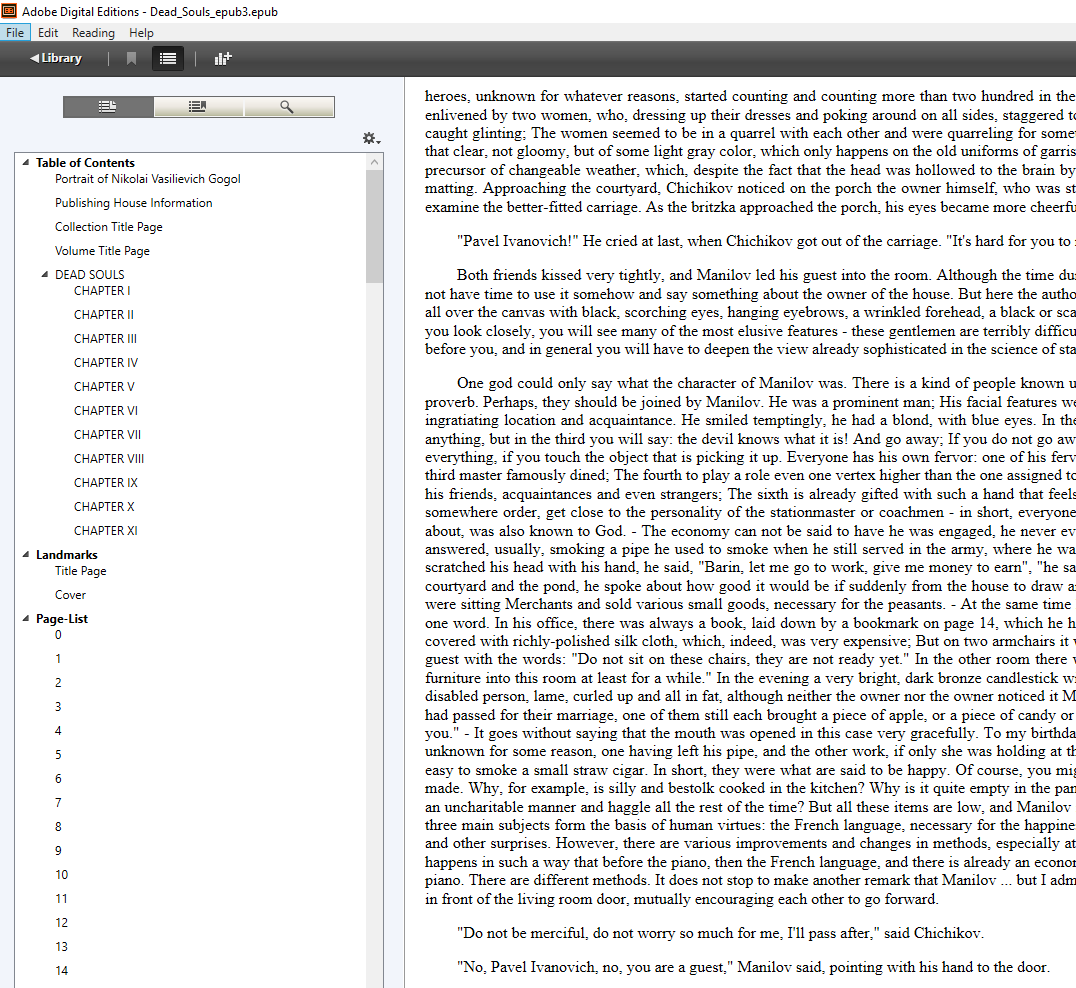
Part 4: Wait, What About That Kindle You Mentioned?
Here’s the thing. The reason I was so happy about my ADE success is because I had spent upwards of 20 hours spent on this project trying to make page numbers appear on a Kindle. Usually, when a file is converted, the Kindle doesn’t recognize that it has page numbers encoded. That is because, instead of the ePub page list, Amazon uses its own APNX format to keep track of page numbers. I tried sending various variants of the file to my kindle in various ways, and there was no way to get the real page numbers on my kindle. Moreover, ePub3 e-books converted to mobi files were not even registered by my device. You had to go back to your ePub2 file and work from there.
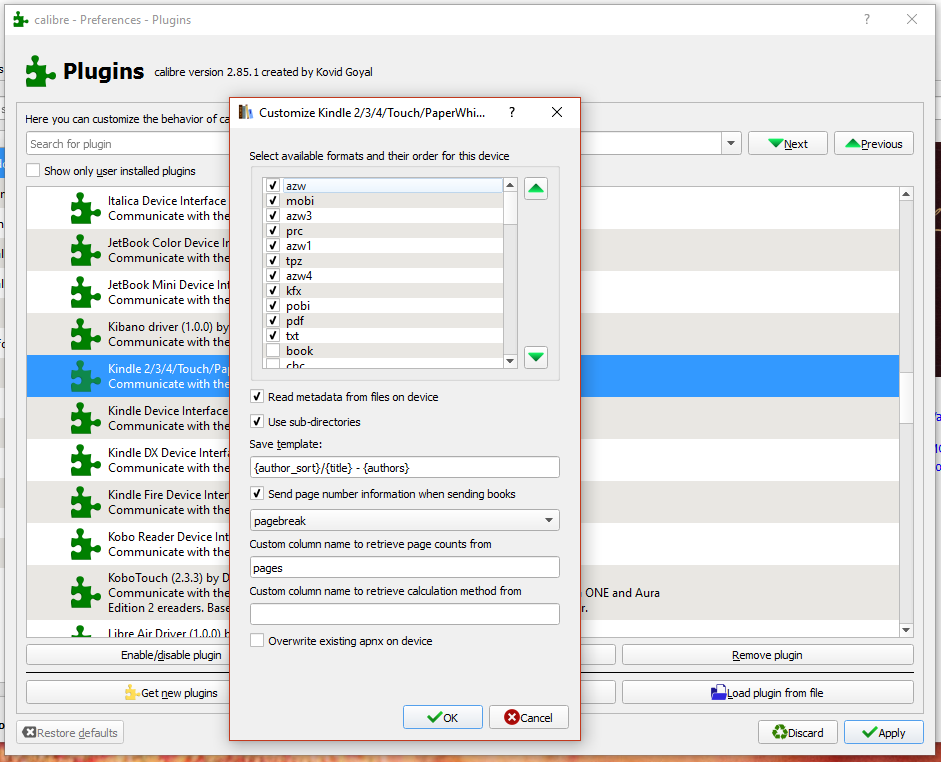
There was, however, another way to make them work. A way that was entirely useless for work with a client, but that could satisfy my pagination needs if I so desired. Calibre has a way to convert things when uploading your files to your device through Calibre that makes your device see a valid APNX file. The catch is that you can’t map it to real page number markers. Instead, what you do is take the number of real pages, input that into a custom column that you created in your Calibre library, and head over to the Settings > Plug-Ins section (make sure you have the most updated version of Calibre!). There, in the Device Interface sub-section, you’re your Kindle version and choose to allow Calibre to “Send page number information when sending books” and to retrieve the page counts from whatever you named your custom column. Then, when you send your book, Calibre averages out the words per page for you, and makes your kindle register that data.
In other words, unless you’re sending a file to your own kindle through Calibre, this process is useless. But it’s fun to know if you like keeping meticulous tabs on your books.
Part 5: So What’s the Payout Then?
You might think that I wasted a lot of time trying to answer this question. After all, forum posts told me this was impossible. Well, here’s the thing. I successfully created an ePub with a page list. I learned how to use Sigil and its Plug-Ins more effectively, I learned about the limitations of Calibre. I worked with various e-Readers like Readium, AZARDI, Adobe Digital Editions in the process of trouble shooting. I worked with Kindle Previewer and Kindle Unpack, and while my efforts were fruitless, I did get good at working with the file type. Not to mention, I also learned some simple Regular Expressions, which left me feeling really clever. I also learned that Calibre has a word sorting feature that might come in handy at some point. Lastly, I thoroughly tested out my second hypothesis and disproved it, so if a client comes asking about whether or not this is possible, I can give them a straight answer. All this experience has also made me more able to work with ePubs in general, so if someone wants to work with Kindle Digital Editions and get real, authentic page numbers included in their file, I know I could pull it off.
I am more empty-handed than I would have wanted at the outset of this project, but my head is chock full of lots of useful information.